本篇介绍 OpenSees 模型管理中的一些实践。对于小模型,一般比较容易维护,所以建模的范式相比于实现功能来讲不是那么重要。但是对于大型项目,为了在模型的建立、扩展、变更、维护的过程中更加方便,有一些范式是值得遵循的。我个人在使用 OpenSees 的过程中,结合多年编写程序的经验,谈谈在 OpenSees 模型管理方面的经验和心得。本篇中涉及的五问分别是
- 管理模型的 TAG:介绍一种便于维护的规则
AxesTagging,通过轴线编号给对象命名; - 创建易复用的函数:介绍编写函数模块的几点注意事项;
- 充分利用注释:介绍注释的重要性和编写方法;
- 参建 LOG 查看模型:通过实例总结前几点,并且通过这一实例帮助图形化模型,方便校对;
- 参数化建模:进一步的实例,介绍参数与模型解耦原则,以及参数化分析的方法。
管理模型的 TAG
在 OpenSees 中,通过 tag 来管理所创建的结点、单元等对象。由于程序没有可视化界面,因此将 tag 进行语义化就显得比较重要。所谓语义化,在前端开发中应用比较多,是指使用恰当的单词来命名 html 标签、CSS 类名等内容,使得所建立的网页结构清晰,有利于团队的开发和维护,也可以通过适当的编辑来修订或扩充内容。然而,在 OpenSees 中,使用数字来定义 tag ,这就导致无法像在前端开发中一样使用单词来管理。但是即始只有数字,我们也可以使这些数字产生规律,从而减少代码维护的困难。
在 OpenSees 中, tag 声明为一个无符号长整型变量。它的最小值是 0,最大值是 232-1=4294967295。其实如果读者朋友尝试使用负数来定义 tag ,会发现程序并不报错。但是对于无符号长整型变量来说,不应该使用其负值,因为它和等外一个正值是等价的,这里不再赘述。既然可以定义这么多位,我们就要考虑充分地利用这些位数,来表达模型的信息。
AxesTagging
基于以上分析,我们考虑使用结构的轴线编号来进行 tag 的命名。这里把这种命名方式称为 AxesTagging 。
在使用 AxesTagging 之间,我们把结构在绘图软件中绘制出来,然后对每一个结点(注意是划分之后的结点),在高斯坐标系下建立轴线网格,并对轴线从 0 开始编号。如果是二维问题,只建立x轴和y轴。而对于三维问题,还要建立z轴。由于网页中展示三维问题比较困难,所以这里用一个二维问题举例。
如图所示,是一个二维框架,高 3 米,跨度 6 米,采用线形单元对框架的梁和柱进行建模。图中已经将网格划分好,为了本文描述方便,每 1 米划分为一段,这样总的单元数不至于太多,仅供举例使用。在实际分析中,想确定网格的划分方法,应当做划分单元数灵敏度分析,找到单元数量和计算精度的平衡。在图中,已对划分的网格进行编号。
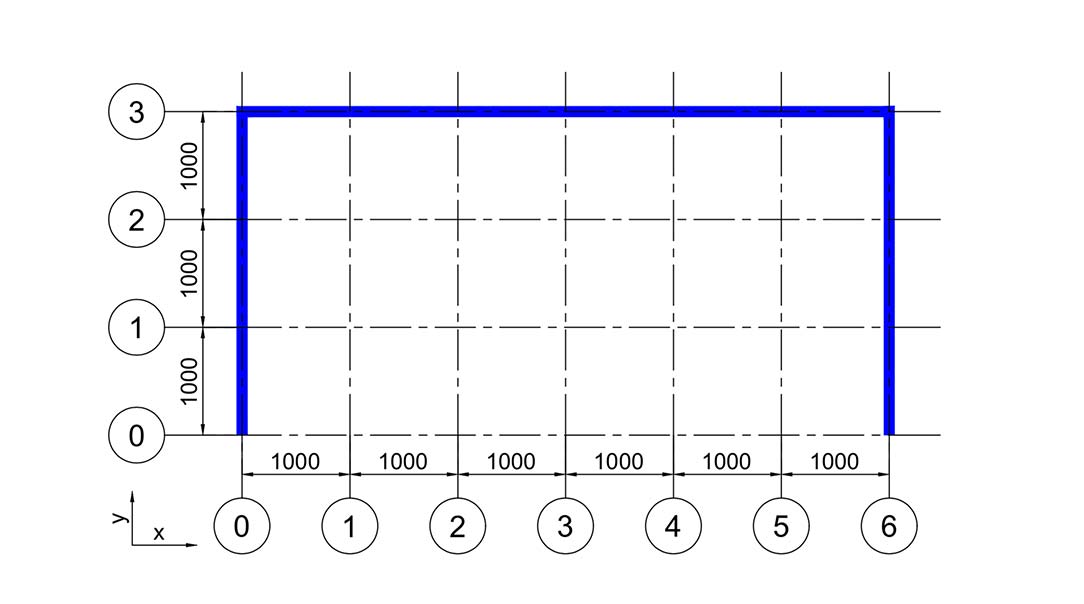
结点编号
下面我们使用 AxesTagging 原则对结点进行编号。这里,对于二维问题,我们用四位数字来代表每一个结点的坐标。这四位数字的前两位代表其所在x方向的轴线编号,而后两们代表y方向上的轴线编号。当然,本例中结点较少,也可以采用两位数字来代表结点坐标。但是在大多数模型中,都应该有不少于 10 条轴线,因些这里也采用了四位数字来表达。如果轴线超过了 99 条,那么就要根据轴线的数量灵活控制编号的方法了。在本例中,以两个梁柱交点为例,其编号和相应的创建结点命令就应该是(采用 N、mm、s 单位制)
1 | model BasicBuilder -ndm 2 -ndf 3 |
好的,我们实现了最初步的 AxesTagging 建模。但是这种建模方式还有一个问题。那就是,在使用 OpenSees 的时候,我们常常会建立一些零长单元,它所连接的两个点的位置是重合的。如果采用坐标轴的方法定义,就无法区分这两个重合的点。因此,我们对所有点引入一个前缀 prefix ,来区别两个获多个重合的点。那么 prefix 的命名规则就是,对于同一个 prefix 下的点,不会出现重合的情况。这个 prefix 就像是为轴网加了一个图层属性,又像是一个命名空间,或者分类,来避免混淆。在本例中,如果我们采用一个零长单元来定义梁柱节点的行为,就可以采用 prefix 把梁和柱区别开。例如,给柱上的点前缀 1,给梁上的点前缀 2。则得到
1 | node 10003 0. 3000. |
这样,每个点归于哪一类,在哪一个位置,就一目了然了。
到了这里, AxesTagging 的优势还没有充分发挥出来。既然已经使用轴线的编号映射到节点的编号,那我们可以通过建立函数,来批量地创建结点。来看代码
1 | proc CreateNode {prefix iList jList XCoords YCoords} { |
这个函数的变量有如下几个
prefix 就是上文中提到的为了分类所使有的前缀,为一个数字。一般 1 位数字就足够使用。
iList 和 jList 是两个 list 类型,分别代表要创建的节点的x方向轴线编号和y方向轴线编号。应该注意的是,所创建的节点是两个 list 的所有相交点。
XCoords 和 YCoords 是两个 list 类型,分别保存每个轴线的坐标。
利用上述函数,可将本例中框架结点的创建命令写为
1 | set XCoords { 0. 1000. 2000. 3000. 4000. 5000. 6000. } |
这样,所有的结点都创建好了。
通常情况下,我们在模型图纸上标注的是两条轴线之间的间距,而不是每条轴线的坐标。这时,可以写简单的函数通过轴线间距来创建轴线坐标。
1 | proc AssembleCoordsList { dList } { |
这样,我们输入轴线间距,再使用这个函数获得轴线坐标
1 | set XDists {1000. 1000. 1000. 1000. 1000. 1000} |
如果在后面的操作中需要获得点的坐标,可以直接通过运算得到,也可以写一个读取器函数
1 | proc GetNodeTag { prefix i j } { |
单元编号
节点建立完成之后,采用类似的方式进行单元编号。多数情况下,单元编号可以与单元中某个节点的编号相同,例如总是使用单元靠左靠下的结点编号作为单元编号,或者采用单元所连接的两个结点的信息拼合而成单元编号,等等。读者可以在使用的过程中自行体会。
对于建筑结构,多数线形构件不是水平就是竖直。有如本例。因此,笔者通常建立两个函数,分别获取水平和竖直向待建立单元的单元 prefix、i 结点坐标、j 结点坐标。我们来看代码
1 | proc CreateVerticalEles { prefix iList jList } { |
在以上的两个函数中,采用的单元命名规则是,如果是纵向单元,就同时包含起点和终点的y方向轴线坐标,而如果是横向单元,就同时包含起点和终点的x方向轴线坐标。这样编号可以使调试更方便。另外,两个函数都使用了 iList 和 jList ,但是在一个函数中两个 list 是不同的。对于 CreateVerticalEles ,其 iList 是指这些竖向的单元x坐标的分布。它可以是一个长度为 1 的 list ,即指只在条轴线上建立单元。而 jList 是指相临单元两端的节点编号,它的长度至少为 2,否则无法建立单元,程序报错。对于 CreateHorizontalEles 则反之。
上述两个程序并不真正地建立单元,而是返回一些 list 。每一个 list 里面包含三个元素,分别是单元的编号,结点 i 的编号,和结点 j 的编号。利用这些编号,我们可以再来建立单元。
利用这两个函数,可以对本例中结构的梁柱建立单元。请看代码
1 | set tsColumn [CreateVerticalEles 1 { 0 6 } { 0 1 2 3 }] |
在建立单元的时候,我们可以把相同属性的单元放在一起建立,这样的话在修改参数的时候只需要修改一次,更容易维护。在本例中,我们假设梁柱的截面属性是相同的,那么就可以通过上述代码统一创建。
那么还有一种比较多见的情况,本例中也要用到的,就是零长单元。这里我们再建立一个零长单元的创建函数
1 | proc CreateZerolengthEles { prefixEle prefix1 prefix2 iList jList } { |
这个函数实现的原理和上面两个函数类似,请读者自行体会。下面我们将梁柱刚接起来
1 | set tsJoint [CreateZerolengthEles 1 1 2 { 0 6 } { 3 }] |
这样,节点就实现了刚接。
这一问中,简单介绍了 tag 管理中我个人推荐使用的 AxesTagging 原则,并给出了几个实例。当然,我们的例子十分简单,读者在实际操作中可能会遇到各种各样的情况,但是万变不离其宗,掌握了这个原则,你会发现,在 debug 和维护大模型过程中不再那么头疼。
创建易复用的函数
很久以前,编程语言大多是面向过程的,比如 Pascal, Lisp, C 等。也就是说,在程序执行的过程中,按照一定的顺序,包括条件选择、循环,甚至 Goto 等,来一步一步地执行。后来,面向对象的编程范式被提出,有了对象的概念,使程序更加模块化,更容易扩展和维护。然而在科学计算中,大量使用面向对象的必要性并不高,而且如果不是大规模合作的话,显得大材小用,没有必要。但是,即使采用面向过程的编程方法,也要注意代码的可维护性,以免出现难以 debug 和维护的现象。因此,创建易复用的函数是非常重要的。
易复用的函数的一个重要特点是,函数不依符于某个特殊的模型存在,在给定特定的参数的情况下,得到的结果是相同的,且参数不会在函数运行的过程中发生改变。 tcl 语言与 python 、 javascript 等语言不同,其 list 不是一个指针类型,在函数传值时,传递的是 list 本身,而不是这个 list 的指针。因此,函数的参数是很难被改变的,这一点被自动约束住了。
在上一问中,我们编写了一些函数,就可以用来复用。这里,我们把与 AxesTagging 有关的函数集合起来,编写到一个文件中。由于是在二维空间中的,我们把这个文件命令为 AxesTagging2D.tcl 。文末的源代码下载中,您可以在 modules 文件夹中找到这个文件。
在函数的建立过程中还要注意以下几点原则。
- 函数名称、变量尽量语义化。这里推荐使用驼峰命名法(Camel Case)。驼峰命名法又分大驼峰法和小驼峰法,以首字母是否大写来区分。由于在
tcl编程中一般不使用面向对象中“对象”的概念(在其它语言中一般用大驼峰法命名对象),所以笔者推荐把用大驼峰法定义函数,用小驼峰法定义变量。例如,定义函数GetNodeTag用来获取一个nodeTag等。 变量命名也有一定的规则。例如,布尔类型的变量一般用表示判断的动词开头,如hasKey、isEmpty等,list类型的变量使用复数来命名,与非list类型的变量区分,如names表示一个元素为name的list。对于不会变化的常量,用全部字母大写、单词之间用下划线分隔的方法,例如INTEGRATION_TYPE等。 - 函数的不要使用全局变量,而是通过函数参数传递变量。如果使用全局变量,即使不改动函数的定义和输入参数,如果全局变量发生了改变,也会使函数结果发生变化。因此,在写可复用的函数时,不应使用全局变量。事实上,
tcl语言为了约束这一行为,全局变量并不暴露在函数体中,隐性地防止了这一情况的发生。但是,在一些情况下,比如在某个模型中我们为了简化建模过程而创建的不需要复用的函数中,可以使用global命令,引用全局变量。 - 函数要合理地处理异常。在很多情况下,用户的输入并不符合预期,这就需要函数引发异常并处理。至少要在控制台中打印异常信息,以便用户调试。最不理想的情况是,函数读取的变量不正确,进行了错误的处理,但是没有输出任何错误信息,导致一切混乱。
- 要编写合适的函数文档,以便日后的维护和其它用户的使用。这一点在下一问中具体分析。
创建好了可复用的函数之后,可以把一个函数或一组函数保存在一个独立的 .tcl 脚本文件中。在建模时,使用类似于 model.tcl 的文件名来命名主模型,再把可复用的函数保存在一个用类似于 modules 命名的子目录中,再在 model.tcl 中使用 source 命令来引用这些函数。再建立一个以类似于 out 命名的子目录来保存输出结果,程序的结构就非常清晰了。
充分利用注释
充分地利用注释,可以让你的程序结构更清晰,也更容易维护。事实上,在很多无图形界面 Server 版 Linux 系统中,打开其 config 文件,会看到大量的注释,比实际被读取的代码要多很多。我们在写程序的时候,虽然不需要写得那么详细,但是也要充分地利用注释带来的便利。
大纲级别
首先,就像每篇文章会分成章、节、目等大纲级别一样,程序也是有大纲级别的,每一段内容在做什么,应该用注释加以区分。而且,对于不同的级别,可以使用不同形式的注释。对于高级别的注释,可以使用复杂的花纹边框等方式使其醒目,如
1 | ################## |
在某些大型项目中,我甚至会使用一些 ASCII 符号拼合成的单词作为高级别的注释,这样在编辑器边的代码地图中就可以看到,十分方便。这种风格在 DOS 时代几乎每个程序都会使用。网上有一个有趣的ASCII 单词生成器,感兴趣的读者可以打开链接玩玩。对于其它级别的注释,也可以通过注释符号的数量,与代码之间空行等方式来进行区分。
另外一个推荐使用的做法,就是在代码的最前面加上一段 front-matter。这是对这段代码文件的基本信息的记录。里面可以包含一段对代码内容的简介,创建和修改时间,代码的使用方法等的记录。
我们在修改和调试代码的过程中,往往会产生很多版本。这时就应该使用一些版本控制的手段来明确历史版本和修改内容。这时读者们会想到 git 和 svn 两种版本管理系统。我本人也是在采用 git 来对自己编写的程序进行版本管理。但是, git 系统查看日志、回滚版本的命令也比较复杂,有的时候不尽如人意,所以我对一些重要的版本,即能产生出结果,在某种程度上可以满意的版本,直接通过复制和归档代码的方式来保存。这时,我会在主代码的 front-matter 中做版本的记录,使用一个整数加一位小数来管理版本,小的修复和改动时,提升小数位的数字。大的修改和重要版本变化时,提升整数位的数字。同时,每一次版本提升时,做了哪些改动,都在 front-matter 中加以记录。这样所有的版本都可以追溯,也不用担心修改的时候把模型彻底破坏了。
下面举例说明注释的使用方法
1 | ##################### |
如此,文档就更方便管理了。
下面再介绍两个使用文档注释中的 tricks。
“画”出信息
第一,对于 OpenSees 模型,我们可以使用 ASCII 在文档中“画”出一些信息,使结构一目了然。例如,在划分 H 形截面的程序中,我画了如下的图
1 | # Graph: |
这样,创建者和使用者都可以一眼看出,截面是什么样子的,轴线与截面的关系等。
再举一例,在 PushoverStaticAnalyze 函数的定义中,我定义的参数之一是目标变形 list ,加上一个图表,就使函数的功能一目了然。
1 | # Graph: |
使用 TODO 等关键字
第二个 trick 是在注释中使用关键字。有的时候,为了编程的连贯性,经常先调用函数再定义,或是先用一个代替符、代替数来占位等等。为了以后的不会忘记,可以使用 TODO: 、 FIXME: 等关键字在注释中记录下来。在实际运行程序之前,用查找功能找到这些关键字,再一一修复,就避免了事后忘记。在很多编辑器中,也有插件支持提取所有具有类似关键字的位置。
创建 LOG 查看模型
下面我们来实践可复用的函数的创建。在 OpenSees 建模中,由于没有图形界面,所以把结构的形态输出成图片,观察所建结构的几何位置是否正确是建模过程中的一个重要环节。下面我们就来编写一个函数 OpenSees2YAML ,把 OpenSees 模型输出为 YAML 的格式。关于 YAML 的语法,在这篇文章中有详细的介绍。简单来说,它是一个用最少的符号来创建一个键-值对对象的语言。下面直接来看代码
1 | ############################# |
上面这段程序实现了输出结构中结点和单元的一些基本信息,可以用于调试模型。在使用时,把上述代码保存到 modules 文件夹的 OpenSees2YAML.tcl 中,然后可在自己的模型中调用。一般是在建模完成后,开始分析之前调用。示例如
1 | source modules/OpenSees2YAML.tcl |
利用任何其它语言对 structureLog.yml 文件稍加处理,就可以将结构的形态和振型绘制出来。如果使用 python ,可以引用 pyyaml 库;如果使用 javascript ,可以直接使用 JSON.parse() 函数。这里不再赘述了。
读者从这段程序中,可以自行体会本文所述的变量命名、易复用函数、利用注释等编程技巧。源代码可以在文末的源码下载中找到。
参数化建模
使用 AxesTagging 的另一个好处就是可以方便地实现参数化建模。比如我们可以把轴线的间距定义为参数,在分析过程中直接调整参数的值,就可以调整整个结构了。
参数和建模解耦
在使用 OpenSees 建模时,对于有可能要进行参数化分析的模型,推荐一律使用参数化建模的原则来编写程序。在这里,参数化建模的原则是指,把参数和建模完全解耦。这就要求把程序分解为前后两个部分。在前一部分,只进行参数的定义。而在后一部分,利用前面定义的参数来建模。解耦的最终目标是,在正式分析时,不管如何修改前面的参数部分,后面的建模部分始终保持不变。这就避免了短次修改参数都要改动程序体,最后记不清哪里发生变化现象的发生。
在实际应用中,经常会涉及到一系列参数化分析。例如 IDA 分析,灵敏度分析,易损性分析等。这时,我们可以通过简单的几个步骤,把用参数化建模原则编写的程序改装成执行参数化分析的程序。
以本例的 portal frame 为例,假设我们要对使用不同截面但是相同尺寸的这一结构进行 IDA 分析,那么我们利用参数化建模的原则和 AxesTagging 原则编写如下代码,并保存为 model.tcl
1 | #################### |
在这个模型中,为了简单,假设梁和柱使用的截面相同,都是高、宽为 200mm,翼缘和腹板厚度都是 14mm 的 H 形钢。假设结构质量集中在两个梁柱节点上,两个节点上的质量各为 15t。梁柱刚接,不考虑 P-∆ 效应。考虑重力和地震两种荷载。地震输入文件放在 source 目录中,虽然这里放了三个文件,分别是 accel0.txt 、 accel1.txt 、 accel2.txt ,但是为了方便,其内容都是一样的,可以点此下载。运行程序,可以得到在 PGA=0.4g 的 0 号地震波作用下,结构的最大侧向位移。读者仔细阅读这段程序,就会发现,所有的可变参数都定义在 PARAMETERS 部分。
参数化分析
现在我们要做一个简单的 IDA 分析,只需要把上面的 model.tcl 文件进行修改,把整个模型定义为一个函数,把要参数化分析的变量作为函数的参数定义,把关心的量作为函数的返回值。然后再多次调用这个函数。这里为了区别,新建一个模型文件,命名为 paramStudy.tcl 。
注意:
- 在函数体的最前面,加上
wipe命令,以清空上一个模型所占内存; - 引用模块的
source语句提到最前,不需要多次引用; - 把函数体中被提为函数参数的定义去掉;
- 为了加快速度,在写函数时,把如
OpenSees2YAML这样调试用的函数注释掉; - 对于大型参数分析,可以把函数定义和执行分成两个文件。这里为方便写在了一个文件里。
1 | source ... |
这样,在控制台中就输出了与 PGA 相对应的结构侧向位移最大值。
下面我们举一个例子,回顾一下一个完整项目的目录结构。
- ProjectFolder/
- model.tcl
- paramStudy.tcl
- out/
- nodes.txt
- eles.txt
- modules/
- Function1.tcl
- Function2.tcl
- source/
- accel.txt
- versions/
- v1.0/
- model.tcl
- figure.png
- out/
- v2.0/
- v1.0/
代码下载
本篇源代码可以点击下载。


