def__init__(self, target_spectrum, period_bound=None): self.motions = [] self.factors = np.array([], dtype=np.float32) self.spectrums = [] self.target_spectrum = target_spectrum # period bound defaults to the domain if period_bound isNone: period_bound = [0.0, target_spectrum.periods[-1]] self.period_bound = period_bound # create sample points in the period matching boundary self._period_samples = np.linspace(period_bound[0], period_bound[1], self._period_sample_number) # create an SOE to optimize the factors self._spectrum_matrix = None self._target_vector = target_spectrum.get(self._period_samples) defset_motions(self, motions, factors=None, spectrums=None, damping=0.05): self.motions = motions if factors isNone: self.factors = np.ones([len(motions)]) * 0.01# trick: make a obviously small initial factor else: assertlen(factors) == len(motions), "Length of factors and motions are not identical." self.factors = np.array(factors, dtype=np.float32) if spectrums isNone: self.spectrums = [Spectrum.from_accel(mo.accel, mo.dt, damping) for mo in motions] else: assertlen(spectrums) == len(motions), "Length of spectrums and motions are not identical." self.spectrums = spectrums self._reset_spectrum_matrix() def_reset_spectrum_matrix(self): mat = np.zeros((len(self._period_samples), len(self.motions))) for i inrange(len(self.motions)): spectrum = self.spectrums[i].get(self._period_samples) mat[:, i] = spectrum / len(self.motions) self._spectrum_matrix = mat self._target_vector = self.target_spectrum(self._period_samples)
defsaveable(mode="wb"): defdecorator(fn): defdecorated(self, filename=None): res = fn(self) if filename isnotNone: withopen(filename, mode) as f: f.write(res) return res return decorated return decorator
defloadable(mode="rb"): defdecorator(fn): defdecorated(data=None, filename=None): if filename isnotNone: withopen(filename, mode) as f: data = f.read() if data isNone: raise ValueError("data is None or cannot be loaded.") return fn(data) return decorated return decorator
@saveable("w") defsuite_to_json(self, filename=None): return json.dumps({ "motion_strs": [mo.to_json() for mo in self.motions], "factors": self.factors.tolist(), "spectrum_strs": [spe.to_json() for spe in self.spectrums], "period_bound": self.period_bound, "target_spectrum": self.target_spectrum.to_json(), })
@loadable("r") defsuite_from_json(data=None, filename=None): it = json.loads(data) target_spectrum = Spectrum.from_json(it["target_spectrum"]) su = Suite(target_spectrum = target_spectrum, period_bound=it["period_bound"]) motions = [Motion.from_json(mo_json) for mo_json in it['motion_strs']] factors = it["factors"] spectrums = [Spectrum.from_json(spe_json) for spe_json in it["spectrum_strs"]] su.set_motions(motions, factors, spectrums) return su
# Bound these methods outside class definition, for this notebook only. Spectrum.to_json = spectrum_to_json Spectrum.from_json = staticmethod(spectrum_from_json) Motion.to_json = motion_to_json Motion.from_json = staticmethod(motion_from_json) Suite.to_json = suite_to_json Suite.from_json = staticmethod(suite_from_json)
@saveable() defmotion_to_bytes(self, filename=None): data = b"" nlen = len(self.name) ilen = len(self.info) data += struct.pack("i", nlen) data += struct.pack("i", ilen) data += struct.pack(f"{nlen}s", self.name.encode("utf-8")) data += struct.pack(f"{ilen}s", self.info.encode("utf-8")) data += struct.pack("d", self.dt) data += self.accel.tobytes() return data
@loadable() defmotion_from_bytes(data=None, filename=None): nlen, ilen = struct.unpack("ii", data[:8]) data = data[8:] (namebt,) = struct.unpack(f"{nlen}s", data[:nlen]) data = data[nlen:] (infobt,) = struct.unpack(f"{ilen}s", data[:ilen]) data = data[ilen:] (dt,) = struct.unpack("d", data[:8]) data = data[8:] accel = np.frombuffer(data, dtype=np.float32) name = namebt.decode("utf-8") info = infobt.decode("utf-8") return Motion(name=name, dt=dt, accel=accel, info=info)
@saveable() defsuite_to_bytes(self, filename=None): mlen = len(self.motions) motions = [mo.to_bytes() for mo in self.motions] spectrums = [spe.to_bytes() for spe in self.spectrums] motion_bt_len = [len(bt) for bt in motions] spectrum_bt_len = [len(bt) for bt in spectrums] target_spectrum_bt = self.target_spectrum.to_bytes() array_len = np.array(motion_bt_len + spectrum_bt_len + [len(target_spectrum_bt)])
data = b"" data += struct.pack("dd", self.period_bound[0], self.period_bound[1]) data += struct.pack("i", mlen) data += array_len.tobytes() for mo_bt in motions: data += mo_bt for spe_bt in spectrums: data += spe_bt data += target_spectrum_bt data += self.factors.tobytes() return data
@loadable() defsuite_from_bytes(data=None, filename=None): period_bound = struct.unpack("dd", data[:16]) data = data[16:] mlen, = struct.unpack("i", data[:4]) data = data[4:] lenslen = mlen * 2 + 1 lens = struct.unpack(f"{lenslen}i", data[:lenslen*4]) data = data[lenslen*4:] motions = [] spectrums = [] for i inrange(mlen): motions.append(Motion.from_bytes(data[:lens[i]])) data = data[lens[i]:] lens = lens[mlen:] for i inrange(mlen): spectrums.append(Spectrum.from_bytes(data[:lens[i]])) data = data[lens[i]:] lens = lens[mlen:] target_spectrum = Spectrum.from_bytes(data[:lens[0]]) data = data[lens[0]:] factors = np.frombuffer(data, dtype=np.float32) assertlen(factors) == mlen, "Factors length does not match." suite = Suite(target_spectrum=target_spectrum, period_bound=list(period_bound)) suite.motions = motions suite.factors = np.array(factors, dtype=np.float32) suite.spectrums = spectrums return suite
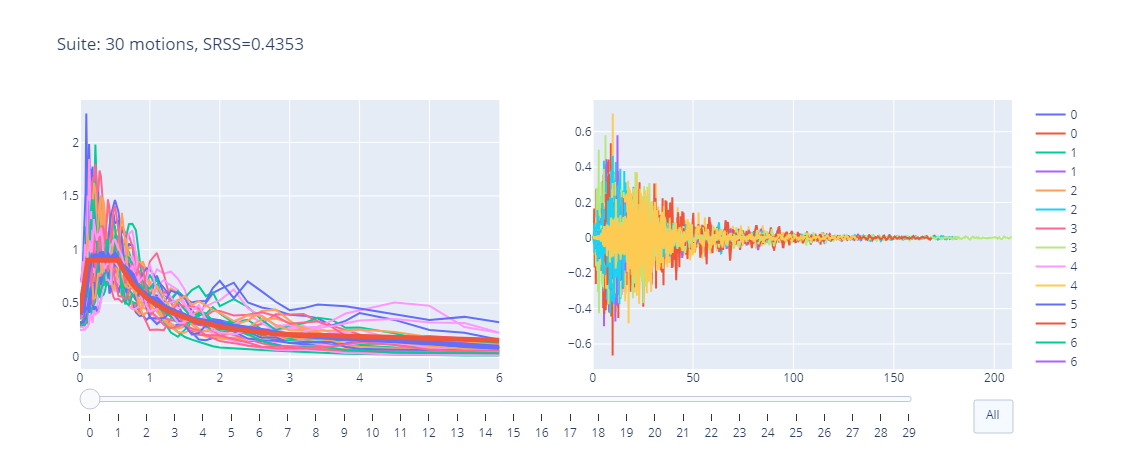
ss = pe.Suite.load("sample.suite") ss.plot_interactive()
# copy ss to a new Suite instance target_spectrum = Spectrum(periods=ss.target_spectrum.periods, values=ss.target_spectrum.values) s = Suite(target_spectrum=target_spectrum, period_bound=ss.period_bound) motions = [Motion(name=m.name, dt=m.dt, accel=m.accel, info=m.info) for m in ss.motions] factors = ss.factors spectrums = [Spectrum(periods=s.periods, values=s.values) for s in ss.spectrums] s.set_motions(motions=motions, factors=factors, spectrums=spectrums)
# Save time print("--- Save time for json") %timeit s.to_json(filename="s1.json") print("--- Save time for bytes") %timeit s.to_bytes(filename="s2.bytes") print("--- Save time for pickle") %timeit s.to_pickle(filename="s3.pkl") print("--- Save time for mat") %timeit s.to_mat(filename="s4.mat")
# Load time print("--- Load time for json") %timeit s1 = Suite.from_json(filename="s1.json") print("--- Load time for bytes") %timeit s2 = Suite.from_bytes(filename="s2.bytes") print("--- Load time for pickle") %timeit s3 = Suite.from_pickle(filename="s3.pkl")
from os.path import getsize # File size print("--- File size for json") print(getsize("s1.json"), "bytes") print("--- File size for bytes") print(getsize("s2.bytes"), "bytes") print("--- File size for pickle") print(getsize("s3.pkl"), "bytes") print("--- File size for mat") print(getsize("s4.mat"), "bytes")
--- Save time for json 79.1 ms ± 2.7 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) --- Save time for bytes 1.45 ms ± 26 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each) --- Save time for pickle 999 µs ± 20.7 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each) --- Save time for mat 16 ms ± 281 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) --- Load time for json 110 ms ± 2.67 ms per loop (mean ± std. dev. of 7 runs, 10 loops each) --- Load time for bytes 2.91 ms ± 196 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) --- Load time for pickle 281 µs ± 20.1 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each) --- File size for json 2978618 bytes --- File size for bytes 533810 bytes --- File size for pickle 589685 bytes --- File size for mat 549144 bytes